Understanding Thai Sentence Structure
Using the X-Bar Theory of Phrase Structure
Rattasit Sukhahuta
Computer Science Department, Faculty of Science
Chiang Mai University
239 Huaykaew Rd. Suthep, Muang, Chiangmai, Thailand
rattasit.s@cmu.ac.th
Abstract
The ambiguity of Thai language structure is important and needs to be addressed since it is a bottle-neck for further analysis processes. In this research, we describe the design of phrase structure grammar and development of grammar parser that assigns grammatical structure to annotate input text with label brackets. Natural language parser is a language processing tool that recognizes the structure of the sentence according to the specified grammar rules. The rules for parser usually are defined in lexicalized and context-free. In this study, the words with multiple syntactic categories are disambiguated with part-of-speech tagger that reduces ambiguities of the sentence structure. The head word appears at the beginning of each context that plays important role in deciding category of the phrase. The results of the parser will be displayed as a tree structure called syntax tree. The information source is in the form of unstructured natural language of Thai text. The approach to the problem is divided into two parts. First, the Thai written language is processed with morphological analysis and each word is assigned a part-of-speech tag. Second, the phrase structure grammar (PSG) rules for the Thai language are defined in a form of Extended Backus–Naur Form (EBNF) with the principles of phrase structure and the X-bar theory that aims at the common properties of different types of syntactic constituents.
Keywords: Information Extraction (IE), Thai Languae Processing, Thai NLP
1. Introduction
In-depth NLP analysis requires large amount of knowledge and computational resources, nevertheless, it provides the system with an ability to enhance its level of language understanding. In computational linguistics, syntactic information is used to identify the role words play within the sentence and their semantic meaning. In recent years, there are number of researches related to Thai language processing. The ORCHID project was focusing on building large part-of-speech corpora and that is part of the research at National Electronics and Computer Technology Center (NECTEC), the research institute in Thailand. Many researches for Thai Treebank has been proposed such that Ruangrajitpakorn presented Thai CG Treebank a language resource where the tree can be divided into three grammatical types [9] and the corpora tool kit is also developed in [7].A dependency parser for Thai is also described with the composition of three components [11]. First is the process of root identification followed by the dependency analysis and finally, the proposed algorithm based on the beam search. Nevertheless these research still requires tremendous amount of works from linguists in order to derived large annotated corpus. Thus sentence parsing tools are very important to analyze grammatical structure research and development increases analysis of the structure of language. For the sentence parsing tools that perform structural analysis of the language such as CMU Link Grammar. Thai character cluster (TCC) [10] used a set of few simple rules to character clustering to reduce the ambiguity of word boundary in Thai documents and to improve the search efficiency. A Thai LFG tree [5] is transformed into the corresponding English LFG tree by pattern matching and node transformation. An equivalent English sentence is created using structural information prescribed by the English LFG tree. This paper is organized as followings. Section 2 explains the characteristics of Thai sentence and the challenges when dealing with its ambiguity. Section 3 describes the experiments of our implementation. Finally, the conclusion of this paper is presented in Section 4.
2. The Characteristic of Thai Sentence
The structure of Thai text often contains highly ambiguous structure. The sentences usually are written consecutively without a boundary between words or sentences. Usually, the spaces will be used to separate the contexts; but they cannot be used as an indicator for beginning or ending of the sentences. There are many different ways that Thai words can be created such as compounding, reduplicating, deleting and loaning. Thai has no word inflection for different case, sex or gender; therefore, the word form will not be changed. There is only one form of words for different syntactic categories. For instance, a word go will be in the same form for all tenses and gender. Thai sentence formation usually relies on the semantic meaning rather than the grammar structure. In this research, the input sentences are segmented and tagged with part-of-speech tags using SWATH, a language processing tool [4] Part-of-Speech (POS) tagging is one of the common techniques used in the syntactic analysis of sentences. The common Thai part-of-speech tagging usually contains 12 general syntactic categories[1]. The syntactical categories used are generic syntactic categories, which are not specific enough to describe the role of the words. This is important because Thai has no word inflection and in particular, it allows words with the same syntactic category to appear in serial such as serial nouns, verbs, auxiliaries and determiners. In addition, this general classification does not include all syntactic categories such as punctuation marks and prefixes which can be inserted in front of the verb to nominate it. For these reasons, we need the assistance of the syntactic categories designed by the Orchid project [14]. In the Orchid tagset, there are 14 general categories that have been further classified into 47 categories. For instance, the noun is divided into six different nouns: NCMN, NPRP, NCNM, NTTL, NLBL and NONM.
2.1 Thai Phrase Structure Grammar
In Thai, a phrase is a higher level grouping of words, which may be noun phrase (NP), verb phrase (VP) or prepositional phrase (PP). The phrase is usually composed of one or more elements, where each element can be a specifier or complement of other words. In Thai, any single word that has a role in the sentence can also be considered as a phrase. Phrases can be linked together to form larger phrase and eventually, the hierarchical structure for the entire sentence is formed. In this research, the X-bar theory is used to describe the phrase structure grammar of the Thai language. This means that the structure will be represented as layers in a hierarchical representation. The phrasal categories containing a group of words are organized into noun phrase (NP), verb phrase (VP) and prepositional phrase (PP) and they must contain at least one lexical element head.
2.2. Proposed Context Free Grammar
In this study, we organize the Thai phrase into five main phrasal categories (NP, VP, PP, ADVP, ADJP) and six lexical nodes (LBL, CONJ, END, INT, PUNC) in the grammar. The difference between the phrasal category and the lexical node is that the phrasal constituent may contain hierarchically structure that takes other constituents as the complement whereas the lexical node may appear by itself as a single tree node. The action codes in the grammar are omitted for an ease of presentation in this paper. Using ANTLR [7], the grammar rules are deterministically parsed in a top down manner with a fixed amount of look-ahead. Rules are first defined and procedure is given for determining if a context free grammar is LL(k) [9]. It also uses bottom-up parsing in a new Grammatical Transformation into LL(k) form [6]. Although, some theorems of LL(k) had iteration [2], parsing LL(k) techniques are still widely used. For example, Extended LL(k) grammars and parsers [8]. Adding semantic and syntactic predicates to LL(k): pred-LL(k) cannot resolve syntactic ambiguities and parsing conflicts due to the limitations of finite look ahead.
The context-free grammar rule contain the rule elements of the left hand-side that can be rewritten by the rules on the right hand-side. The elements that can be decomposed further to smaller elements are called “non-terminal”, whereas the others that cannot be decomposed are called “terminal elements”. For this case, the terminal rules are the part-of-speech tags that are assigned to the segmented words. The CFG rules for Thai are defined in the EBNF (Extended Backus–Naur Form). The symbols ‘*’, ‘+’, ‘?’ are the regular expressions notation for the quantifier that indicate ‘zero or more’, ‘one or more’ and ‘zero or one’ (optional) respectively. Although, the notion of the sentence in Thai is not clear but in the phrase structure rule will start the highest node as the sentence. The basic structure of Thai sentence is in the following order: Subject-Verb-Object, but sometimes some constituents such as subject or object can be missing. In PS(3) the rule allows different phrasal constituents to appear in the sentence.
3. Experiments
We have developed a Thai parser a software application with ANTLR (ANother Tool for Language Recognition) is a language tool that provides a framework for constructing recognizers, interpreters, compilers, and translators from grammatical descriptions (http://www.antlr.org) [9] The notation of the Orchid tagset consisting of 47 POS tags was also exploited. The rules consist of non-terminal nodes where part-of-speech tags appear as the leaves. The parser development is based on the phrase structure grammar rules with the focus on optimizing the pre-processing of linguistic analysis. The parsing technique used in this study is based on top-down parsing that looking for syntax tree starting from the root node and works down to leaves at the bottom of a tree. The grammar rules use an extended Backus-Naur Form (EBNF) notation, which describes the non-LL(k)/LR(k) context-free languages. The top-down parsing strategy with syntactic predicates augmented solve non-LL(1) designed to provide selective backtracking and semantic predicates to any context sensitive tree pattern. Basically, the parser is divided into two modules. First, the scanner, or the lexical analyser, scans the input stream from left to right to recognize the valid strings called tokens, the scanner works on the basis of deterministic finite automata (DFA), which uses regular expressions. Second, the parser recognizes the phrase structure of a group of words according to the predefined grammar rules. The followings are results from the parser based on input sentence that is segmented and tagged with part-of-speech.
![]()
“people receives message to notify that the number operating 900 Mhz band will be expired in the year 2558”
The result from the parser is in the format of labeled brackets, and represented in a tree structure with the visualize tool (Fig 1).
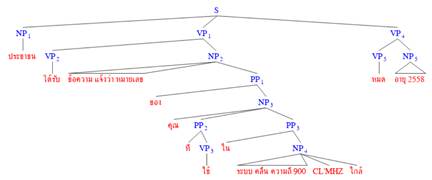
Fig 1: Parsed results from the parser in tree structure
The evaluation is performed based on the Grammatical Relations (GRs) based on parser views of the sentences with a form of head and dependency schemes as described in the followings:
Modifier: mod (type, head, dependent)
The relationship between the head and its modifier can be examined using this scheme. In CFG, the modifier such as adverb phrase, adjective phrase and classifier node are presented as a separate node from the lexical head.
Subject: subj (head, dependent, initial_gr)
The subject argument can normally be found from the lexical head of the noun phrase node. However, since Thai language does not require an overt subject or a pronoun to appear in the sentence, the subject information can be omitted from the subj slot-filler's scheme. It is important to note that the phrase structure can begin with any phrasal constituents. Therefore, the subject information can be located in a different sentence or as a separate tree node. For this case, the subject scheme will not be considered. Another important issue that should be addressed here is that the grammar rules allow the nouns and verbs series to be presented as N' and V' nodes.
Complement: comp (head, dependent)
A relation between the head and the complement can be captured using the comp scheme. This scheme is designed to capture the complement information in general. Within the complement, the information such as direct and indirect objects can be further identified.
Direct object: dobj (head,dependent, initial)
Direct object information usually resides within the noun phrase node that may be a complement of the verb phrase. Usually, a direct object is a result that receives directly from the action of verb. According to Orchid's syntactic categories, the action verb has a form an active verb (VACT).
Indirect object: iobj (type, head, dependent)
An indirect object contains information which is an indirect result received from the direct object. An indirect object in Thai usually follows the direct object and normally is introduced by the preposition.
In this experiment, 266 sentences are selected from the import/export domain, which have also been divided into 3 test sets. The performance of the parser according to the four schemes: mod, subject, direct object and indirect object, will be evaluated based on the precision of the results [3].
No. of slot produced by the parser
GR Precision = ----------------------------------------
No. of expected slots
|
Test Set |
T1 |
T2 |
T3 |
Average |
|
Mod-Head |
93.86 |
95.45 |
87.52 |
92.28 |
|
Sub-Verb |
78.32 |
83.63 |
79.86 |
80.60 |
|
Direct-Obj |
88.35 |
97.31 |
98.34 |
94.67 |
|
Indirect-Obj |
97.35 |
97.39 |
96.44 |
97.06 |
Table 1: The experiment results of the GR schemes
Table 1 illustrates the experiment results of GR precision that are produced by four different schemes. This result shows that the verb-subject relationship has the lowest percentage of 80.60%. One of the reasons is that the VP node is not attached to the correct noun phrase node in the syntactic tree. Based on this experiment, the problem of the Subject-Verb relation in Thai is difficult to deal with due to three main reasons. First, there is no subject-verb agreement such as gender and plural. Any noun phrase node that appears before the main verb is eligible to become a subject. Secondly, there are many help words used in the sentence as to clarify the meaning. Sometimes, these additional words that appear between the actual subject and verbs cause the confusion to the parser. Finally, since Thai has no sentence boundary and there are no specific punctuation marks used within a sentence, the parser can only rely on the space that is used as the context separation. In this experiment, the parser has no problem in identifying the direct or indirect object. This is because an object usually immediately follows the verb in the Thai word order. However, the results of action may appear more than once which can be scattered in different places or conjoined with another events using the conjunction. In this situation, the object that usually resides within a noun phrase node may be incorrectly attached to the verb phrase node.
4. Conclusion
This paper describes the Phrase Structure Grammar (PSG) that have been developed the Thai grammar rules using the Orchid tagsets. We emphasized on using X-Bar theory for constructing the Thai phrases and context-free grammars including noun phrase, verb phrase and prepositional phrase and the additional phrasal nodes (e.g. classifier, labeling, ending and punctuation) are introduced into the phrase structure. Since the development of the parse is beyond the scope of this research, we therefore used ANTLR language translator tool to provide the syntactic predicates to parse the sentences via arbitrary expressions using semantic and syntactic context. With this approach we could be able to automatically create the annotated sentences in bracket labelling which is the preliminary important steps for building large Thai Treebank corpus.
References
[1] T. B. Adji and B. Baharudin. 2007. Annotated disjunct in link grammar for machine translation. In International Conference on Intelligent and Advanced Systems (ICIAS 2007).
[2] John C. Beatty. 1977. Iteration theorems for LL(k) languages (Extended Abstract). In Proceedings of the ninth annual ACM symposium on Theory of computing - STOC ’77, pages 122–131, New York, New York, USA. ACM Press.
[3] John Carroll, Ted Briscoe, and Antonio Sanfilippo.1998. Parser evaluation: a survey and a new proposal. In Proceedings of the 1st International Conference on Language Resources and Evaluation, pages 447–454. Citeseer.
[4] P. Charoenpornsawat. 2003. Swath: Smart word analysis for thai.
[5] Tawee Chimsuk and Surapong Auwatanamongkol. 2009. A Thai to English Machine Translation System using Thai LFG tree structure as Interlingua. In Engineering and Technology.
[6] M. Hammer. 1974. A new grammatical transformation into LL(k) form (extended abstract). In Proceedings of the sixth annual ACM symposium.
[7] Krit Kosawat, Nattapol Kritsuthikul, and Thepchai Supnithi. 2005. Thai Copara Toolkit. In PACLING.
[8] Y.J. Oyang and C.C. Hsu. 1982. Extended LL (k) grammars and parsers. In Proceedings of the 20th annual Southeast regional conference, pages 240–245. ACM.
[9] T. Parr and R. Quong. 1994. Adding semantic and syntactic predicates to ll (k): pred-ll (k). In Compiler Construction. T. J. Parr and R. W. Quong. 1995. Antlr: A predicated-ll(k) parser generator. Software: Practice and Experience, 25:789–810, july.
[10] D.J.
Rosenkrantz and RE Stearns.
1970.
Properties of deterministic top-down
grammars. Information
and
Control, 17(3):226–256.
[11] T.
Ruangrajitpakorn, K.
Trakultaweekoon, and T.
Supnithi.
2009.
A syntactic resource for thai:
Cg
treebank. In
Proceedings of the 7th Workshop
on Asian Language Resources.
[12] T.
Theeramunkong, V.
Sornlertlamvanich, T.
Tanhermhong, and W.
Chinnan.
2000.
Character cluster
based thai information retrieval. In
Proceedings of the fifth international
workshop on on
Information
retrieval with Asian languages.
[13] S.
Tongchim, R.
Altmeyer, V.
Sornlertlamvanich, and H.
Isahara.
2010.
A dependency parser for
thai.
In Proceedings
of The sixth internationalconference on Language Resources and Evaluation,
volume 10.
[14] Sornlertlamvanich
Virach, Charoenporn Thatsanee, and
Isahara Hitoshi. 1996.
ORCHID:
Thai
part-of-speech
tagged corpus. In
Orchid, TRNECTEC-1997-001,
pages 5–19,
April